[As with the previous post, this thread was originally posted on Twitter, but since I’ve stopped using that platform, I’m retroactively publishing it here.]
A short thread on *ordle games and parallel computation. /1
… is a nice analogy for SIMD (single instruction multiple data) parallel programming. /5
Vector processing is the best known form of SIMD, where your data changes, but all operations are done in parallel. And that’s effectively what the higher n variants of Wordle look like. /6
Each “operation” in this SIMD analogy is a guess and, because you use fewer guesses per word, you can see the benefit of parallelization, but only because there are more words to reveal. /7
Just looking at Wordle, Dordle, and Quordle, they each allow n+5 guesses for an n word puzzle. However, as n goes up, I think you could reduce the constant factor; with an n>100 or so, I suspect n+2 or n+3 guesses would be sufficient for all games. /8
That is, make two initial guesses (e.g., RAISE and COUNT as I do). At that point, the process of elimination should enable correctly identifying a few of the unknown words. Filling in the letters and positions for those words, will give enough information for a few more words… /9
And so on until you’ve guessed everything. /10 (fin)
[I wrote this originally as a thread on Twitter, but since I’ve stopped using that platform, I’m retroactively publishing it here, slightly reformatted.]
A thread about Wordle, letter frequencies, and how the choice of corpus matters for textual analysis.
I’ve only been playing Wordle for about two weeks, so I can’t claim any expertise, but it tickled some old interests of mine and then I got a little obsessed. /1
Wordle’s rules are similar to those of one of my favorite games as a kid, Mastermind, except Wordle requires that guesses and answers be words rather than colored pegs. This is a big difference, which I’ll say more about below! /2
It’s clear that the starting guess in Wordle is important and there are articles talking about picking good ones. (E.g., The Best Starting Words to Win at Wordle.) /3
The general idea is you want to use common letters for two reasons: one, they’re more likely to be in the answer, and two, if you learn they aren’t in the answer, you can eliminate a large swath of words. /4
That letter frequency analysis works in Wordle is one reason it’s different from Mastermind: there’s no a priori distribution of color pegs which can lead to a useful strategy. /5
Back in third or fourth grade, I got a copy of Herbert Zim’s Codes & Secret Writing from the Scholastic Book Club and its list of most common letters – ETOANRISH, in order – is cemented in my brain. (I have a a weaker sense that DLU come next.) /6
Based on that, when I started playing, my first pair of words would be ORATE and CHINS. They get all of Zim’s first nine, with three vowels in the first word and a “C” thrown in. Not too bad. /7
I switched for a few games to HATER/BISON for reasons that don’t make much sense (“B” is rarer than “C”), but missed having the three vowels in the first word. /8
Then I got a little empirical and asked myself “Is Herbert Zim’s 1966 frequency table still right?” Language doesn’t change very quickly, but this is 2022 and it’s easy to check for yourself. /9
I found free, sample corpus of news articles on the web that could be downloaded, did a very little of scripting and, for that corpus, the first half of the alphabet by frequency is ETAOINSRHLDCU. /10
(By the way, Peter Norvig, a friend, colleague, and mentor of mine across two jobs and my boss in my early years at Google, did a similar analysis based on Google Books with similar results.) /11
ETAOINSRHLDCU is pretty similar to Zim’s order – with I and S moving up a little and R moving down. Nothing too interesting yet. /12
But then I started thinking about Wordle specifically and the frequency of letters in general text is not that interesting for the game, since Wordle only uses five-letter words. /13
If we restrict to five-letter words in the same corpus, we get a very different distribution: EARTSOIHLNDUC. Vowels (except U) are relatively more popular and T and N drop a lot. /14
Why T and N? Well, here are the most common ten words in this article corpus, with counts:
96786 the 44855 to 44855 of 41891 and 35282 a 32805 in 17630 that 16638 is 16080 for 13759 on
None of those words are five letters, but the distribution of letters in those words, because they’re so common – they’re the “head” of a “long-tailed” (or Zipfian) distribution – strongly affect the frequencies of letters in English text. /16
To give one example, looking at the full article corpus but dropping just the word “the,” the most common letters become EATOINSRLDHCU: without “the,” T drops from 2nd to 3rd and H from 9th to 11th. /17
Definite articles like “the” (or “le”/“la” in French) are very common words. The effect in English is probably larger than other languages because it’s non-gendered, so there’s only one such word. (“a”/“an” are split, but not due to gender.) /18
One anecdote about the outsized effect of “the” on English… /19
In its early days, Google didn’t index “the”: it was omitted from both docs and queries. Circa 2000 – before my time – they started indexing it, but to not reduce index size, that cost adding ~25 machines to each thousand-machine serving cluster for the extra data. /20
Getting back to Wordle, all these issues of word frequency actually make the letter frequency tables much less relevant, because Wordle is drawing from some list of five-letter words where the frequency of those words (probably) doesn’t matter. /21
Why not? My assumption is that Josh Wardle is choosing words that are common enough that people don’t say “Is that really a word?” but doesn’t care that COAST is twice as frequent as METAL in a corpus of news articles, Either COAST or METAL is a fine Wordle word. /22
This means computing letter frequencies on general text – even if restricted to just the five-letter words – will probably mislead you if you’re trying to guess words in Wordle. /23
These are the ten most frequent five-letter words in the corpus I’m using:
4994 their 3679 which 3609 there 3430 about 3218 would 2698 after 2292 other 2155 first 2065 years 1874 could
So, instead of using a corpus of articles, a simple wordlist with no frequency information should give more useful insights. I’m using the /usr/share/dict/words that comes with MacOS and dropping words that contain capital letters (proper nouns) or other symbols. /25
There are 8497 five-letter words on that list meeting my criteria. But, many of the words wouldn’t be fun if they were the answer in Wordle: AALII, TOYON, CHORT, LENIS, SERUT, etc. If I had to guess, at least 50% would be too rare for the game. /26
But, which 50%? I thought about intersecting the list with words that passed some frequency threshold in the news corpus, but this is just an approximate exercise, so I went with the list as is, TOYONs and all. /27
The most common half of the alphabet in that list is AEROISTLNUYCD. That’s quite different from Zim’s list. A is more frequent than E! T and H are way down in popularity! (H drops to #14.) /28
Based on this list, I revised my opening Wordle guess to AROSE. Unless I have some insights based on the results of my first guess, I follow that with UNTIL (or UNLIT). /29
Can one do better? Well, machines can, especially if they know the word list (or a reasonable superset). How? By exhaustively keeping track of which words are impossible once the results are known from previous guesses. /30
(Spoiler alert: what follows are examples from a few days ago. By the time you’re reading this, if you’re playing Wordle, you’ll have safely seen them. But maybe you’re somehow saving Wordle games for later?) /31
For example, if today’s word were POLAR and you guessed AROSE, the YELLOW/YELLOW/YELLOW/GREY/GREY result only matches 117 words from my dictionary. /32
Similarly, if today’s word were SHIRE and you guessed AROSE, you’d get a GREY/YELLOW/GREY/YELLOW/GREEN that would match only 25 words on that list. /33
For a human, picking what word would distinguish best among those 117 or 25 words is a hard task, but a computer can just try all the words and see what reduces the number of possibilities most for the next round. It turns out, the space of words is very sparse. /33 [Oops! Two 33s!]
This gets at another difference between Wordle and Mastermind. In Mastermind, any combination of colored pegs is acceptable. In Wordle, it’s only (roughly, at most) 8497 words out of 26^5 = 11,881,376 possible combinations of five letters, or roughly 0.07%. /34
Based on some automated exploration, I think RAISE may be the “optimal” initial guess if the word list I’m using is close enough to the actual one used in Wordle. But, there’s not as “nice” a generic followup guess for it as AROSE/UNTIL; COUNT or MOUNT come close. /35
At worst, after guessing RAISE/COUNT, there would only be 98 possible word choices, for my word list. With MOUNT as the second word, it’s 90. HOTLY would reduce the possible set to 83 words and POUTY or PYLON, 89. /36
Since I switched to RAISE/COUNT as my default guesses, I’ve been solving the daily Wordles in three or four guesses, which feels a little better than before. But it may just be luck of the draw, in terms of the word of the day. /37
Summary:
While Wordle has similar rules to Mastermind, using words makes it very different.
Letter frequencies based on list of unique words versus real text differ a lot.
Only ~0.07% of five-letter combinations are words.
(I wrote this letter this morning, after seeing from Matt Cutts and Daniel Tunkelang that the Patent Office was soliciting guidance on patents following the Bilski decision. I wrote it quickly and it’s less polished than I would have liked, but thought it was worth posting anyway. For more information, see what the FSF has to say.)
To the United States Patent Office,
I am a US citizen and software engineer. I am a named inventor on at least three patents (numbers 7,346,839, 7,409,383, and 7,783,639) and am named as an inventor for numerous pending patent applications. I am employed by Google, Inc.; this letter represents my personal opinion and not necessarily that of my employer.
Software patents are a significant threat to innovation in the software industry and, by extension, all of America’s technology-related businesses. While I understand the theoretical case that software patents can foster innovation – by encouraging investment and advancing the state of the art through disclosure – I have not seen this to be the case in any way in the software industry.
On the issue of investment, there is no case I can think of in the software industry where a patent has lead to investment in a company that succeeded due to the patent’s franchise preventing competitors from developing an equivalent product. Instead, the pattern for patent litigation and threatened litigation – as you are well aware – is for successful companies to be approached by non-practicing entities for damages or fees, with little or no money ever reaching the original inventors or their investors. Copyright and trade secrets do not have the same problems as patents and have proven very successful for protection in the software industry.
On the issue of disclosure, it should be noted that many, but not all, software “inventions” described in patents are inherently disclosed by making a product available to users. In many other cases, rather than disclosure, realizing that a problem has been solved encourages others to attempt solutions. Some of those solutions may be independent rediscoveries of the same underlying algorithm; others may be different algorithms, but in either case. The lifetime of patents make disclosures from software patents nearly useless – and fundamentally detrimental – as contributions to the state of the art; by the time the application period and twenty years have passed, many generations of software technology have passed.
Because software patents inherently give an exclusive franchise for algorithms that may be independently discovered, it is impossible for a software engineer to opt-out of the patent system. This coercive nature of software patents has forced many practitioners, myself included, to apply for patents against our wishes, because we want to ensure that we are allowed to exploit our inventions. And it is this potential for independent discovery of algorithms that exist independent of their applications that underlies a moral argument against patents.
In addition, the practical implementation of software patents has been terrible and damaging to the industry: the criteria for novelty are far too loosely applied, allowing many obvious applications to covered by patents; multi-year application processes lead to widespread adoption of techniques – including as part of industry standards – before a patent covering them is issued; and the language of patents and claims are so far removed from the working language of computer scientists that it is often difficult for an inventor to read his or her own patent and understand whether it covers the intended invention.
Speaking as someone who has worked in the software industry for more than two decades and as a former entrepreneur, a world where software companies competed on building the best products and independent discovery of algorithms is recognized as a legitimate, non-infringing activity would be vastly preferable to the current state of affairs, where work that appears obvious can lead to years of litigation about infringement. I urge you to reject all software patents, on both moral and practical grounds.
I just participated in a phone poll from some outfit (Western Wats) calling with caller ID saying 801-823-2023. Occasionally, I’ll do these things out of curiosity about what they’re asking, but this one really offended me by how blatantly the questions were directed to a particular result (and how clumsily done that was).
The “poll” was clearly commissioned by carriers opposed to net neutrality. It started with a set of questions to gauge how engaged I was in politics and technology: Do I read news sites online?Do I post comments on blogs? It then moved on to questions about broadband internet policy: Should the government “regulate the internet”?Does Congress have more important things to do than regulate the internet?Should internet service providers ensure “routine internet usage” isn’t disrupted by “large file transfers”? (Is YouTube routine? How about Netflix-via-TiVo? Amazon’s MP3 downloads? Just to name three routine things I’ve done in the past 24 hours…) The last set of questions were looking for agreement with fairly confusing premises, all of which were along the lines that net neutrality would undermine all these good things the internet can do. For example, do I agree that we shouldn’t regulate the internet if/because doing so would prevent empowering the poor to use the internet? (No, I don’t agree.) At the end, parsing the questions, I felt as if I was continually being asked “Have you stopped beating your wife?”
I have no problem with carriers opposed to net neutrality polling to figure out where their message resonates. But this “poll” crossed an ethical line, giving questions with no good answer for people who disagree with their point of view. Perhaps most polling is of this stripe, but I’ve responded to a fair number of phone polls and none of the previous ones was this crass in driving towards a specific result.
I spent a little time playing The New York Times’s Times Reader 2.0 this evening and it’s pretty nice. It gives what appears to be a full copy of the day’s Times in an easy to browse format. Cut and paste works. And doing the crossword puzzle on it was fun. If I were planning a plane flight, I’d definitely use this for offline access to a newspaper.
(This was also the first Adobe Air application I’ve used. I was quite impressed with how smooth the Air experience is and how zippy and close to native the application feels.)
One flaw: the search is based on substrings, not full words, which makes it feel very low precision. Searching for [star trek] in today’s paper showed results about “states to start” and “Representative Pete Stark.” But there are so few documents in a given day’s paper that search probably isn’t a very big issue.
But, showing a newspaper’s typical cluelessness about the web, the Times Reader doesn’t provide a way to get a URL for the article you’re reading. That’s inane. This is 2009. They want people to link to their articles. They want people to tweet them, to share them, to post them on Facebook. The Times knows this: they have share buttons on all articles on their website. The Reader even has a way to send a link to an article to an email address. And they link to “Times Topics” pages from inside the articles, so it’s clear they know how to embed URLs properly. But as far as I can tell, there is no way to just click a button and go to the article in a web browser, so that I can just share it. Instead, if I’m reading something I want to pass on, I’ll need to search for it again on the web to find a URL.
Do they just not want to participate in the conversation?
At one point on the outbound flight, Susan was reading the Times her Kindle, Matthew was playing on his DS, Allie was watching The Little Mermaid on Susan’s iPhone, and I was catching up on work email on my laptop. All the devices got used quite heavily on the trip.
I compare this to traveling a little more decade ago, when Susan I were on the road for a few months straight and had nothing closer to any of these than a compact 35mm camera. (We did use a lot of payphones and internet cafes, though, and picked up the International Herald Tribune when possible.)
I had resisted getting a “smartphone” for a while. I’d had a Palm III in the mid ’90s and didn’t find it something I really integrated with my life. I’d also had some ugly Sprint Phone in the late ’90s that let me browse news headlines and check mail at Yahoo, but it was painful enough to use that I never really got hooked. Then I switch to AT&T for a while for a much nicer phone and realized that, at the time, what I wanted was a phone that worked. When AT&T discontinued TDMA support without having a suitable presence of GSM towers in my neighborhood, I switched back to Sprint with a phone whose sole advantage was a rubberized case that could survive being dropped. I lasted with that for a few years — it worked fine as a phone and wasn’t too large. Given my limited experience with internet-enabled phones and PDAs, the bulky ugliness of BlackBerries and Palm devices, and my general resistance to anything branded as running Windows, I didn’t feel the need to get one.
Then, Steve Jobs pre-announced the iPhone. Like most technophiles, I swooned. Phone/iPod/camera/browser/PDA. Real internet access. The usability which I love Apple products for. And the prettiest device I had ever seen. So, I figured, I’d stick with my Sprint contract until the iPhone actually came out and then switch.
What intervened was that I started to make more phone calls for a few months, went over the 700 monthly minutes in my existing Sprint contract, and was charged the usurious rates they charge when you go above your limit. I called Sprint, told them I wanted to increase the calling time in my plan, but was told I could only do so by starting another two-year contract. Sorry, no.
By that time, the cool kids around the office were carrying the BlackBerry Pearl. It was small. It was available on AT&T, which I knew I was going to switch to, in order to get an iPhone. It was internet-enabled.
For me, the Pearl was the perfect email device. I didn’t use BlackBerry email, since I’m addicted to gmail’s threading, but the gmail mobile app is very well done. And the Pearl’s two-letters-per-key keyboard is very easy to type on — I can probably type on it at half the speed of a full-size desktop keyboard. Google Maps Mobile is similarly excellent. And, in addition, it could browse the web, but neither the built-in browser nor Opera were very good and, on the small screen, there was only so much of a browsing experience one could hope for.
Perhaps I’m too easily sold on a new device and too willing to compromise, but I really liked the Pearl. It was so much more functionality than I’d had before that I was totally hooked. I got used to reading things on it and wrote tens of email messages on it a day. It was good enough that, for the most part, I stopped carrying my laptop around the office. “Good enough” is an important criteria: anything that replaced it had to be better in enough dimensions to be worth the switch.
I was happy. Despite my original plan, I was going to stick with my BlackBerry, at least until there was a physical keyboard on the iPhone and, more important to me, a decent, native implementation of gmail.
On the other hand, Susan had gotten an iPhone last year and I’d become comfortable with it; ok, I was coveting it. On a vacation where we had poor GSM/Edge coverage but good WiFi, it worked very well (though modern BlackBerries do, too). I used the web interface to gmail on it and was more than pleasantly surprised. And I found that it was more important to me to have a well-rounded internet device than just a good email device. So I switched, even knowing that the device I was buying would be (hopefully) obsolete in a couple of months, due to the mythical 3G iPhone.
Now that I’ve switched, I can’t believe I held on to the BlackBerry as long as I did. What I’ve found is that I use the iPhone less for email than I used the BlackBerry, but much more in general. The phone experience on it is much more pleasant than I’d expected. The few native apps work nicely, but it really shines as an internet device. One shout-out: the new Google Reader beta for the iPhone is one of the most addictive apps I’ve ever used. And I’m very excited by the possibility of native apps, now that the SDK is out.
Of course, the iPhone still has its compromises. The lack of a keyboard does hurt, but I’m typing better than I had expected and wouldn’t want to give up any screen space or make the device larger. I’m hoping that with downloadable iPhone apps, we get an iPhone version of gmail mobile. (Despite working for Google, I have no idea if such a thing is in progress.) The Edge network is terrible once you’re used to anything faster, but the 3G rumors give my hope. And I still carry my iPod Nano with me, because the GSM interference (aka, BlackBerry buzz) is really awful when I use the iPhone hooked up to my car’s stereo.
So, is it the ultimate phone/mobile internet device? No, but it’s better than anything else I could actually buy today. And it’s a very satisfying piece of “realized science fiction” that I can carry around with me. It’s good enough for now.
I’ve been a very happy Netflix subscriber for almost a decade. The wide selection of movies and lack of pressure about returning at any particular time works really well for me. We all know that
Netflix’s rent-by-mail model will be replaced by net-based delivery before too long, but the video-on-slow-demand model has been more than good enough — if it went away without something better replacing it, I’d be upset. And so far, nothing seemed better from a convenience standpoint: I wanted to watch on my TV, not hook up a full computer to the TV, use a normal remote control, and pay a fixed price per month for whatever we watch.
Last week, I ordered the Roku Netflix player and it arrived tonight. Setting it up took about five minutes, the bulk of which was trying to reach the outlet behind the piece of furniture underneath the TV. After it was running, we could watch any of the “watch instantly” titles from our queue. Took about five to ten seconds after selecting something for it to start playing.
The UI is pretty minimal, which is exactly what one wants. Rather than a fancy device which does a lot of things, this plays movies from Netflix. Period. Pausing, rewinding, and fast forwarding all work with a nice, Coverflow-esque UI. Queue management is not done on the player but on a normal web browser on some other machine.
The biggest drawback is that the selection available to watch instantly is still limited — about 10% of the things on my DVD queue were available for instant watching. That doesn’t bother me, because we’ll keep up our usual Netflix subscription and use this as a supplement until the world ends up cutting over to online delivery.
The other drawback we’ve hit is that you don’t have access to subtitles from the DVD. Apparently closed-captioning may be available for some things, but the subtitles usually interfere much less with programming than closed captions. We tend to watch with the sound fairly low and subtitles on after the kids are in bed. But, we can live with this.
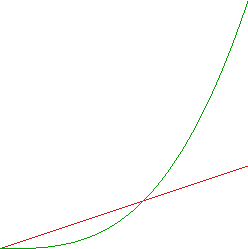
Roy Amara was apparently the person who said “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.” It’s a great observation, but my friend Charles Martin gave me an even better twist on it: “Change happens exponentially but we think linearly.” This is clearly a more specific statement, but, to someone used to thinking in mathematical terms, it gives a strong image of the relative adoption curves.
The reason I like Charles’s version so much, though, is that it also captures the seeds of a reason behind it: spread of a technology is often exponential because, like a disease, we have a probability of transmission from one person to surrounding people. As the “infected” population grows, so does the rate of adoption.